Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser
这文章写的很混乱,读着不容易懂, 但是收获很多。
图像的噪声在raw域可以看作与空域无关,将图像投影到raw域,在raw域加高斯噪声,再投影回来得到新数据。
Albeit the rawRGB noise model is unknown, it generally can be assumed to be signal-dependent and spatially independent [2].
进一步假设ISP是可逆的,使用一个NN去学ISP过程,输入重构输入.
Method
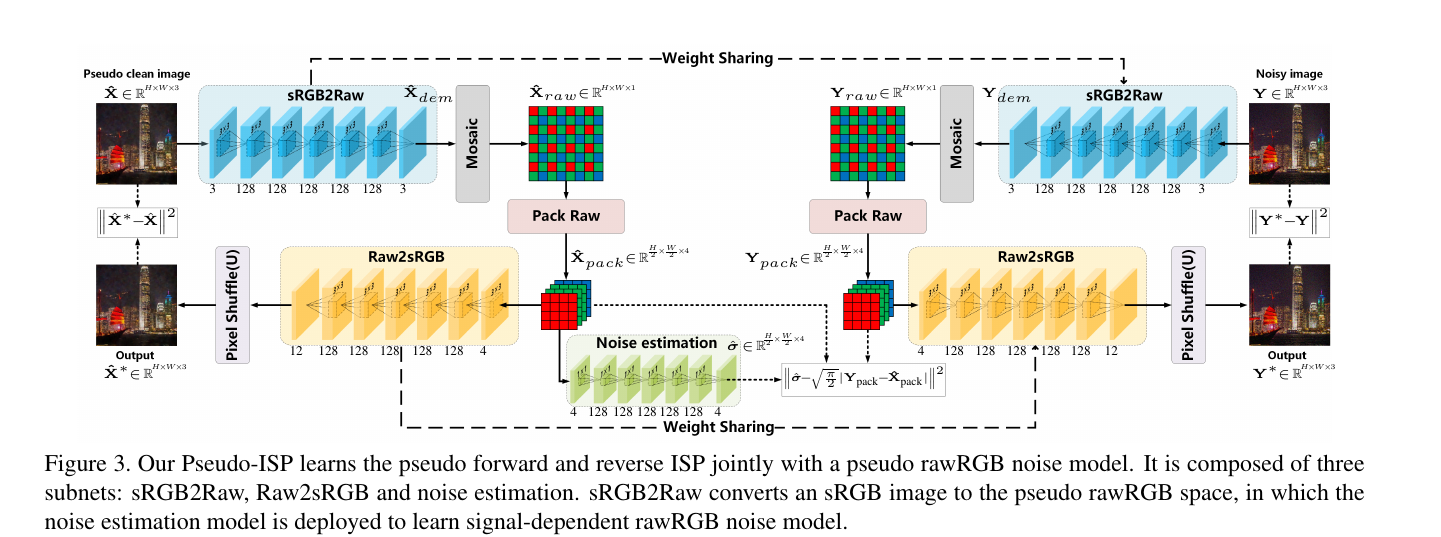
训练PseudoISP :
给出一张来自test(真实数据集没有GT的噪声图) $Y$ , 以及该图 $Y$ 经过pre-train denoiser的假去噪后的图像:pseudo clean image $\hat{X}$ , 进行训练. 将图像投影到RAW域,其噪声应该是可分离且空域无关的(至于单个pixel的值有关。) 将 $\hat{X}$ 输入到噪声估计网络中 $1\times1$ 的卷积网络该噪声强度 如果这个noise是符合高斯分布,那么这个sRGB->RAW的投影就是成功的。具体来说 $Y{raw}^{GT} - {X}{raw}^{GT} = n$ 其中 $n$ 是加性空域无关噪声且符合高斯分布,(raw域噪声)。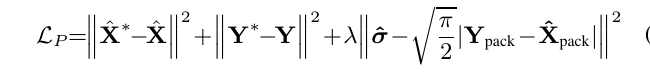
$\sigma$ 是Noise level net的输出。
对于每一张完整的 $Y$ 来说,DND的一张大图。会分割为20张 $512\times 512$ 的图像。每一个512的图像会被分为 $60 \times 60$ 的小patch, $\hat{X}$ 也会做同样的尺寸对齐处理。从而来进行训练。得到50个模型。We randomly crop 12, 000 × 32 patches with size 60 × 60 to train Pseudo-ISP生成数据:
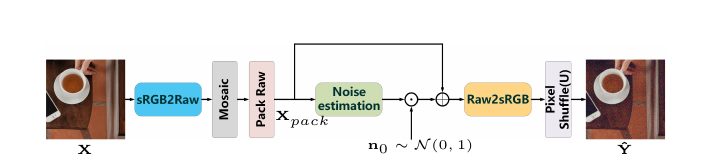
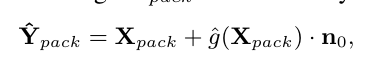
从800张DIV数据集中sample200张出来,抽512大小,每一个512大小的图像用随机使用一个ISP来生成noise图像,以160大小存储。训练AdaptiveDenoiser:
使用了pseudo image and synthetic image pair.
L2 loss。
实验:
数据集:DND, SIDD , SIDDPlus , CC15 and MIT-IP8 as the sets of test noisy images.
- 实验一:
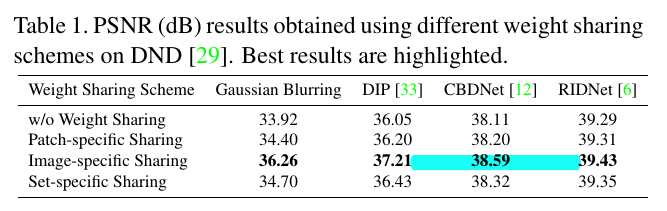
第一个实验是关于weight share的实验,作者指出pseudo-ISP对noise图像和clean图像都是weight share的,是否使用两个不同的网络来区别噪声图和干净图会更加有效? - 实验二:
对于每一个patch模型都是share weights的,即对于DND所有图像而言,才成patch后,都使用同一组pseudo-ISP的模型来进行增强。 - 实验三:
对于每一张DND的图像来说,来自不同图像的patch使用不同的ISP进行增强。 - 实验四:
对于任意图像来自于同一个数据集,使用不同的ISP进行增强。
最后发现对于不同的image进行weight share是最好的,作者的解释是:
DND images are captured using four different cameras which intrinsically do not share the ISP and noise models. Thus, image-specific Pseudo-ISP is adopted as the default.
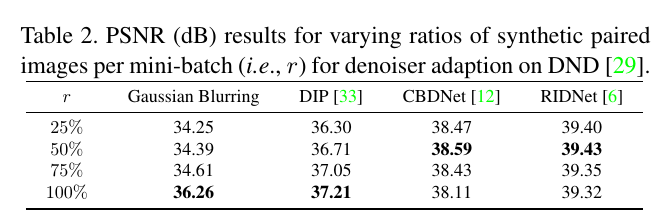
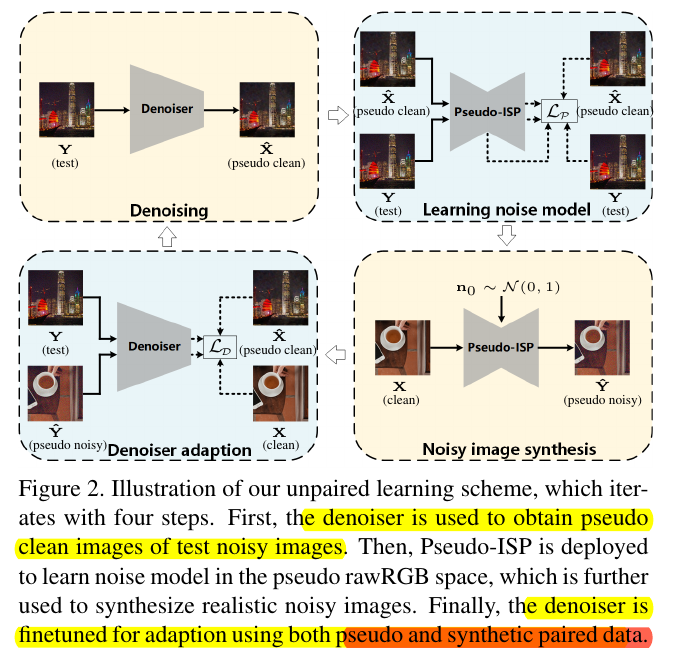
实验:对比生成数据和伪数据的训练结果。
It can be seen that the inclusion of synthetic-noisy set is beneficial to denoising performance. For traditional and unsupervised methods, the synthetic paired set plays a pivotal role and the best performance is attained by only using synthetic noisy images. As for pre-trained deep denoisers, the pseudo paired set can serve as a kind of regularization to avoid the over- fitting to synthetic paired set and thus is required.
实验:不同模型的提升,以及模型在不同数据集上的提升,以及原模型与增强模型的对比: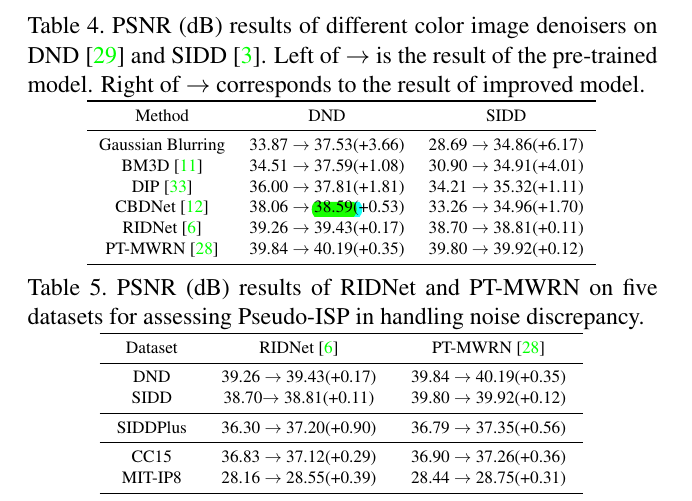

分析
PseudoISP 中, 将Noise 图片 $Y{sRGB}^{noise}$ 经过 NN 得到去噪后的伪去噪图像 $Y{sRGB}^{psd}$ ,假设在RAW 域中噪声独立分布, 将 $Y{sRGB}^{psd}$ 以及 $Y{sRGB}^{noise}$ 投影到RAW域时的noise空域无关。
RAW中Noise空域无关也可以参考void2noise中的挖掉中心点。(对中心点致盲,然后重构中心点,如果假设成立,只能重构空域相关的信息:即只能重构原图信息,不能重构噪声信息)
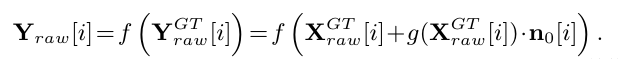
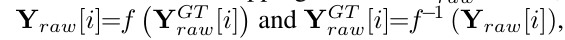
核心: 则 $Y{raw}^{psd} \approx X{raw}^{psd} + h(X{raw}^{psd})\cdot n_0$, 其中 $h(\cdot) = f’(f^{-1}(X{raw}^{psd})) \cdot g(f^{-1}(x_{raw}^{psd}))$ , $f^{-1}() ,f()$ 是GT RAW到Pseudo RAW的转换函数。
告诉我们,在pseudo 域中,仍可以让noise 空域无关。
使核心公式成立需要证明两点:
- 是否能学到 $f()$ 使pseudo raw 到 GT raw的投影? 即:没有RAW 的GT标签,两个image不一定被NN投影到RAW 域, 那么噪声不一定独立,泰勒展开式也不能展开。如果可以,RAW域的noise独立性就可以用泰勒换到psd域。
- 网络能否很好的估计 $h()$ ?如果可以,noisze可以直接添加。


DIV img No. : 601, Patch No. : 0
DIV img No. : 340, Patch No. : 0
总结一下:
UIP -> Cycle-ISP -> Pseudo-ISP
- Cycle-ISP:将UIP中Uprocess和Process操作换成了NN去实现。
- Pseudo-ISP: 基于Cycle-ISP将噪声添加换成了NN并从另一个角度去实现。